
class Solution { public int hex_bitcount(String S); }
that given a string S containing big-endian hexadecimal representation of a non-negative integer N returns the number of bits set to 1 in binary representation of N.
Assume that the length of the string does not exceed 100,000. Assume that the string contains only characters '0', '1', '2', '3', '4', '5', '6', '7', '8', '9', 'A', 'B', 'C', 'D', 'E', 'F'.
For example the function should return 5 when given S = "2F". The string "2F" represents the number 47. The binary representation of 47 is 101111 and it contains 5 bits set to 1.
Algorithm Used: Brian Kernighan’s Algorithm:
Subtraction of 1 from a number toggles all the bits (from right to left) till the rightmost set bit(including the righmost set bit). So if we subtract a number by 1 and do bitwise & with itself (n & (n-1)), we unset the righmost set bit. If we do n & (n-1) in a loop and count the no of times loop executes we get the set bit count.
Beauty of the this solution is number of times it loops is equal to the number of set bits in a given integer.
1 Initialize count: = 0
2 If integer n is not zero
(a) Do bitwise & with (n-1) and assign the value back to n
n: = n&(n-1)
(b) Increment count by 1
(c) go to step 2
3 Else return count
class Solution
{
int hex_bitcount ( String S )
{
int n=0,count=0;
if(S.length()<=100000)
{
n=Integer.parseInt(S,16);
while (n!=0)
{
n &= (n-1) ;
count++;
}
return count;
}
return -1;
}
public static void main(String a[])
{
Solution obj= new Solution();
System.out.println(obj.hex_bitcount("2F"));
}
}
Time Complexity O(logn)
Space Complexity O(1)
Run Here https://ideone.com/9vZ4V
Showing posts with label DirectI Interview. Show all posts
Showing posts with label DirectI Interview. Show all posts
Sunday, June 26, 2011
Friday, June 24, 2011
Given a row of notes (with specified values), two players play a game. At each turn, any player can pick a note from any of the two ends. How will the first player maximize his score? Both players will play optimally.
Problem Statement
Kingdom of Maplewood is a beautiful country comprising of a lot of small islands of different areas. All the islands are in a straight row. King Rosewood is getting old and has decided to divide the islands among his two sons - Eric and Finn. Luckily, the total number of islands is even. He has also decided a few rules for the division of islands:
i) Eric and Finn will be given alternate turns to choose the islands
ii) They can only choose one island at a time from either the beginning or the end of the row of islands.
iii) Once an island is chosen by someone,it cannot be chosen by other person.
Suppose you are Eric and you are given the first choice. Find out the maximum area you are sure you can pick.
Detailed Analysis
so basically There are n coins in a line. (Assume n is even). Two players take turns to take a coin from one of the ends of the line until there are no more coins left. The player with the larger amount of money wins.
1. Would you rather go first or second? Does it matter?
2. Assume that you go first, describe an algorithm to compute the maximum
amount of money you can win.
1st Approach (whether n is even or odd)
if we sort all the coins assume we have array of denominations then it doesn't matter coin odd or even if i start the picking 1st i will definitely win because i will always start 1st or last depending upon sorting.
Although Algorithm will give make sure us that we will win & get the maximum sum but still it don't give us optimal solution don't believe see below.
Time Complexity O(nlogn) So Not Efficient Can we do better.?
2nd Approach (Greedy Approach )
1. Count the sum of all coins that are odd-numbered. (Call this A)
2. Count the sum of all coins that are even-numbered. (Call this B)
3. If A > B, take the left-most coin first. Choose all odd-numbered coins in
subsequent moves.
4. If A < B, take the right-most coin first. Choose all even-numbered coins in subsequent moves. 5. If A == B, you will guarantee to get a tie if you stick with taking only even-numbered/odd-numbered coins. lets run this for 3 2 2 3 1 2 A=3+2+2=7 B=2+3+1=6 A>B so get maximum money that we can make is 7 unit.
although we are able to decrease the time to O(n) to O(nlogn) but still we are sure that we wont get the optimal solution because there can be a test case for which above algo will fail although we will win but won't get the optimal solution .e.g maximum money
Above
Take a Counter test case 3 2 2 3 1 2
A pick left 3 B has two choice left & right 2 no matter what he choose A will choose 2 then we have 2 3 1 left in array so B will definitely choose 2 because he don't have any choice so then a will choose 3 thus making a sum of 3+3+2=8 which more money then what we got in last solution .
So what to do ? we need an efficient algorithm in terms of minimum time & space that can run on big data set as well...yes its sounds like DP..but how we will come up recursive solution , where is overlapping occurs ?
let me explain say we have an array denoted by A1...Ai.....Aj...An .as we always start from any of the end we will come up in middle after some inputs & lets say we are at Ai.....Aj.in array as all before Ai & all after aj have counted by us isn't it.??.
so The remaining coins are { Ai … Aj } and it is your turn. Let P(i, j) denotes the maximum amount of money you can get. the question comes Should you choose Ai or Aj?
so we have two option every time lets choose Ai first then remaining have A(i+1)...Aj for opponent , as he is smart as much you are he will also choose best to maximize the money. so the maximum amount he can get is P(i+1..j).
so lets say we have already computed some for i..to..j denoted by sum(i..j)
so when you choose Ai then maximum amount you can get is say p1
p1=sum(i..j)-P(i+1...j);
& when you choose Aj then opponent have maximum sum denoted by p(i+1..j-1)
then maximum amount you can get is say p2
p2=sum(i...j)-P(i+1...j-1)
then optimal solution can be founded as as we said earlier maximum amount of money we can get when we are in range A[..Aj is denoted by p(i,j)_
P(i, j) = max { P1, P2 }
= max { Sum{Ai ... Aj} - P(i+1, j),
Sum{Ai ... Aj} - P(i, j-1)}
or we write
P(i, j) = Sum{Ai ... Aj} - min { P(i+1, j), P(i, j-1) }
Most Efficient Solution
There is another solution which does not rely on computing and storing results of Sum{Ai … Aj}, therefore is more efficient in terms of time and space. Let us rewind back to the case where you take Ai, and the remaining coins become { Ai+1 … Aj }.
You took Ai from the coins { Ai … Aj }. The opponent will choose either Ai+1 or Aj. Which one would he choose?
Let us look one extra step ahead this time by considering the two coins the opponent will possibly take, Ai+1 and Aj. If the opponent takes Ai+1, the remaining coins are { Ai+2 … Aj }, which our maximum is denoted by P(i+2, j). On the other hand, if the opponent takes Aj, our maximum is P(i+1, j-1). Since the opponent is as smart as you, he would have chosen the choice that yields the minimum amount to you.
Therefore, the maximum amount you can get when you choose Ai is:
P1 = Ai + min { P(i+2, j), P(i+1, j-1) }
Similarly, the maximum amount you can get when you choose Aj is:
P2 = Aj + min { P(i+1, j-1), P(i, j-2) }
Therefore,
P(i, j) = max { P1, P2 }
= max { Ai + min { P(i+2, j), P(i+1, j-1) },
Aj + min { P(i+1, j-1), P(i, j-2) } }
Although the above recurrence relation could be implemented in few lines of code, its complexity is exponential. The reason is that each recursive call branches into a total of four separate recursive calls, and it could be n levels deep from the very first call). Memoization provides an efficient way by avoiding re-computations using intermediate results stored in a table. Below is the code which runs in O(n2) time and takes O(n2) space.
Working Code:
#include
#define MAX(A,B) ((A>=B)? A: B)
#define MIN(A,B) ((A7))
return 0;
if (P2[i][j] == 0) {
counter ++;
P2[i][j] = MAX(A[i] + MIN(maxMoney2(A, P2, i+2, j), maxMoney2(A, P2, i+1, j-1)),
A[j] + MIN(maxMoney2(A, P2, i+1,j-1), maxMoney2(A, P2, i, j-2)));
}
return P2[i][j];
}
int main()
{
int value;
value = maxMoney2(coin_input, P2, 0, 5);
printf("The max money is %d, total calculation: %d\r\n", value, counter);
}
Time Complexity O(N^2)
Space Complexity O(N^2)
Run Here https://ideone.com/l3E3x
Kingdom of Maplewood is a beautiful country comprising of a lot of small islands of different areas. All the islands are in a straight row. King Rosewood is getting old and has decided to divide the islands among his two sons - Eric and Finn. Luckily, the total number of islands is even. He has also decided a few rules for the division of islands:
i) Eric and Finn will be given alternate turns to choose the islands
ii) They can only choose one island at a time from either the beginning or the end of the row of islands.
iii) Once an island is chosen by someone,it cannot be chosen by other person.
Suppose you are Eric and you are given the first choice. Find out the maximum area you are sure you can pick.
Detailed Analysis
so basically There are n coins in a line. (Assume n is even). Two players take turns to take a coin from one of the ends of the line until there are no more coins left. The player with the larger amount of money wins.
1. Would you rather go first or second? Does it matter?
2. Assume that you go first, describe an algorithm to compute the maximum
amount of money you can win.
1st Approach (whether n is even or odd)
if we sort all the coins assume we have array of denominations then it doesn't matter coin odd or even if i start the picking 1st i will definitely win because i will always start 1st or last depending upon sorting.
Although Algorithm will give make sure us that we will win & get the maximum sum but still it don't give us optimal solution don't believe see below.
Time Complexity O(nlogn) So Not Efficient Can we do better.?
2nd Approach (Greedy Approach )
1. Count the sum of all coins that are odd-numbered. (Call this A)
2. Count the sum of all coins that are even-numbered. (Call this B)
3. If A > B, take the left-most coin first. Choose all odd-numbered coins in
subsequent moves.
4. If A < B, take the right-most coin first. Choose all even-numbered coins in subsequent moves. 5. If A == B, you will guarantee to get a tie if you stick with taking only even-numbered/odd-numbered coins. lets run this for 3 2 2 3 1 2 A=3+2+2=7 B=2+3+1=6 A>B so get maximum money that we can make is 7 unit.
although we are able to decrease the time to O(n) to O(nlogn) but still we are sure that we wont get the optimal solution because there can be a test case for which above algo will fail although we will win but won't get the optimal solution .e.g maximum money
Above
Take a Counter test case 3 2 2 3 1 2
A pick left 3 B has two choice left & right 2 no matter what he choose A will choose 2 then we have 2 3 1 left in array so B will definitely choose 2 because he don't have any choice so then a will choose 3 thus making a sum of 3+3+2=8 which more money then what we got in last solution .
So what to do ? we need an efficient algorithm in terms of minimum time & space that can run on big data set as well...yes its sounds like DP..but how we will come up recursive solution , where is overlapping occurs ?
let me explain say we have an array denoted by A1...Ai.....Aj...An .as we always start from any of the end we will come up in middle after some inputs & lets say we are at Ai.....Aj.in array as all before Ai & all after aj have counted by us isn't it.??.
so The remaining coins are { Ai … Aj } and it is your turn. Let P(i, j) denotes the maximum amount of money you can get. the question comes Should you choose Ai or Aj?
so we have two option every time lets choose Ai first then remaining have A(i+1)...Aj for opponent , as he is smart as much you are he will also choose best to maximize the money. so the maximum amount he can get is P(i+1..j).
so lets say we have already computed some for i..to..j denoted by sum(i..j)
so when you choose Ai then maximum amount you can get is say p1
p1=sum(i..j)-P(i+1...j);
& when you choose Aj then opponent have maximum sum denoted by p(i+1..j-1)
then maximum amount you can get is say p2
p2=sum(i...j)-P(i+1...j-1)
then optimal solution can be founded as as we said earlier maximum amount of money we can get when we are in range A[..Aj is denoted by p(i,j)_
P(i, j) = max { P1, P2 }
= max { Sum{Ai ... Aj} - P(i+1, j),
Sum{Ai ... Aj} - P(i, j-1)}
or we write
P(i, j) = Sum{Ai ... Aj} - min { P(i+1, j), P(i, j-1) }
Most Efficient Solution
There is another solution which does not rely on computing and storing results of Sum{Ai … Aj}, therefore is more efficient in terms of time and space. Let us rewind back to the case where you take Ai, and the remaining coins become { Ai+1 … Aj }.
You took Ai from the coins { Ai … Aj }. The opponent will choose either Ai+1 or Aj. Which one would he choose?
Let us look one extra step ahead this time by considering the two coins the opponent will possibly take, Ai+1 and Aj. If the opponent takes Ai+1, the remaining coins are { Ai+2 … Aj }, which our maximum is denoted by P(i+2, j). On the other hand, if the opponent takes Aj, our maximum is P(i+1, j-1). Since the opponent is as smart as you, he would have chosen the choice that yields the minimum amount to you.
Therefore, the maximum amount you can get when you choose Ai is:
P1 = Ai + min { P(i+2, j), P(i+1, j-1) }
Similarly, the maximum amount you can get when you choose Aj is:
P2 = Aj + min { P(i+1, j-1), P(i, j-2) }
Therefore,
P(i, j) = max { P1, P2 }
= max { Ai + min { P(i+2, j), P(i+1, j-1) },
Aj + min { P(i+1, j-1), P(i, j-2) } }
Although the above recurrence relation could be implemented in few lines of code, its complexity is exponential. The reason is that each recursive call branches into a total of four separate recursive calls, and it could be n levels deep from the very first call). Memoization provides an efficient way by avoiding re-computations using intermediate results stored in a table. Below is the code which runs in O(n2) time and takes O(n2) space.
Working Code:
#include
#define MAX(A,B) ((A>=B)? A: B)
#define MIN(A,B) ((A
return 0;
if (P2[i][j] == 0) {
counter ++;
P2[i][j] = MAX(A[i] + MIN(maxMoney2(A, P2, i+2, j), maxMoney2(A, P2, i+1, j-1)),
A[j] + MIN(maxMoney2(A, P2, i+1,j-1), maxMoney2(A, P2, i, j-2)));
}
return P2[i][j];
}
int main()
{
int value;
value = maxMoney2(coin_input, P2, 0, 5);
printf("The max money is %d, total calculation: %d\r\n", value, counter);
}
Time Complexity O(N^2)
Space Complexity O(N^2)
Run Here https://ideone.com/l3E3x
Tuesday, May 31, 2011
WAP to Find Diameter of Binary Tree
Its Really Good Question Because i have found this can be asked in number of ways to make candidate confused. see the number of possible way below.
Find Number of Nodes on the Longest Path in Binary Tree so one thing is sure that this path comprises on two leaves with maximum distance in BT..isn't it
Finding The Longest Path in Binary Tree will use the algorithms used by Diameter of Tree
PS:Don't confused with finding the maximum distance between two nodes in Binary Tree
its completely different algorithm & it has also been solved so u can search in blog.
Algorithm Used to Calculate Diameter/ finding two nodes which are separated by maximum difference.
The diameter of a tree (sometimes called the width) is the number of nodes on the longest path between two leaves in the tree. The diagram below shows two trees each with same 7 as a diameter but different orientation. (also note that there is more than one path in each tree of length nine, but no path longer than nine nodes).

Diameter 7
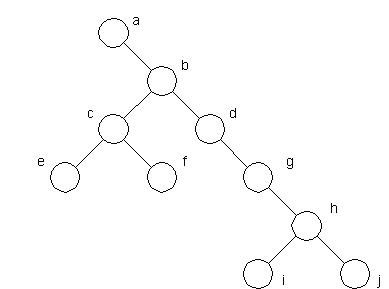
Diameter 7
The diameter of a tree T is the largest of the following quantities:
1 the diameter of T’s left subtree
2 the diameter of T’s right subtree
3 the longest path between leaves that goes through the root of T (this can be computed from the heights of the subtrees of T)
#include
#include
/* A binary tree node has data, pointer to left child
and a pointer to right child */
struct node
{
int data;
struct node* left;
struct node* right;
};
/* function to create a new node of tree and returns pointer */
struct node* newNode(int data);
/* returns max of two integers */
int max(int a, int b);
/* The function Compute the "height" of a tree. Height is the
number f nodes along the longest path from the root node
down to the farthest leaf node.*/
int height(struct node* node)
{
/* base case tree is empty */
if(node == NULL)
return 0;
/* If tree is not empty then height = 1 + max of left
height and right heights */
return 1 + max(height(node->left), height(node->right));
}
/* Function to get diameter of a binary tree */
int diameter(struct node * tree)
{
/* base case where tree is empty */
if (tree == 0)
return 0;
/* get the height of left and right sub-trees */
int lheight = height(tree->left);
int rheight = height(tree->right);
/* get the diameter of left and right sub-trees */
int ldiameter = diameter(tree->left);
int rdiameter = diameter(tree->right);
/* Return max of following three
1) Diameter of left subtree
2) Diameter of right subtree
3) Height of left subtree + height of right subtree + 1 */
return max(lheight + rheight + 1, max(ldiameter, rdiameter));
}
/* UTILITY FUNCTIONS TO TEST diameter() FUNCTION */
/* Helper function that allocates a new node with the
given data and NULL left and right pointers. */
struct node* newNode(int data)
{
struct node* node = (struct node*)
malloc(sizeof(struct node));
node->data = data;
node->left = NULL;
node->right = NULL;
return(node);
}
/* returns maximum of two integers */
int max(int a, int b)
{
return (a >= b)? a: b;
}
/* Driver program to test above functions*/
int main()
{
/* Constructed binary tree is
1 D=4 lh=2,rh=1
/ \
D=3,rh=1 2 3
lh=1 / \
4 5 D=1,lh=rh=0
*/
struct node *root = newNode(1);
root->left = newNode(2);
root->right = newNode(3);
root->left->left = newNode(4);
root->left->right = newNode(5);
printf("Diameter of the given binary tree is %d\n", diameter(root));
getchar();
return 0;
}
Time Complexity (N^2)
Space Complexity O(1)
Run Here https://ideone.com/s9OdR
Optimization(2nd Method)
The above implementation can be optimized by calculating the height in the same recursion rather than calling a height() separately. This optimization reduces time complexity to O(n).
#include
#include
/* A binary tree node has data, pointer to left child
and a pointer to right child */
struct node
{
int data;
struct node* left;
struct node* right;
};
/* function to create a new node of tree and returns pointer */
struct node* newNode(int data);
/* UTILITY FUNCTIONS TO TEST diameter() FUNCTION */
/*The second parameter is to store the height of tree.
Initially, we need to pass a pointer to a location with value
as 0. So, function should be used as follows:
int height = 0;
struct node *root = SomeFunctionToMakeTree();
int diameter = diameterOpt(root, &height); */
int diameterOpt(struct node *root, int* height)
{
/* lh --> Height of left subtree
rh --> Height of right subtree */
int lh = 0, rh = 0;
/* ldiameter --> diameter of left subtree
rdiameter --> Diameter of right subtree */
int ldiameter = 0, rdiameter = 0;
if(root == NULL)
{
*height = 0;
return 0; /* diameter is also 0 */
}
/* Get the heights of left and right subtrees in lh and rh
And store the returned values in ldiameter and ldiameter */
ldiameter = diameterOpt(root->left, &lh);
rdiameter = diameterOpt(root->right, &rh);
/* Height of current node is max of heights of left and
right subtrees plus 1*/
*height = max(lh, rh) + 1;
return max(lh + rh + 1, max(ldiameter, rdiameter));
}
/* Helper function that allocates a new node with the
given data and NULL left and right pointers. */
struct node* newNode(int data)
{
struct node* node = (struct node*)
malloc(sizeof(struct node));
node->data = data;
node->left = NULL;
node->right = NULL;
return(node);
}
/* returns maximum of two integers */
int max(int a, int b)
{
return (a >= b)? a: b;
}
/* Driver program to test above functions*/
int main()
{
/* Constructed binary tree is
1
/ \
2 3
/ \
4 5
*/
struct node *root = newNode(1);
root->left = newNode(2);
root->right = newNode(3);
root->left->left = newNode(4);
root->left->right = newNode(5);
int height=0;
printf("Diameter of the given binary tree is %d\n", diameter(root,&height));
getchar();
return 0;
}
Time Complexity O(n)
Space Complexity O(1)
Run Here https://ideone.com/uSPq0
More Info http://www.cs.duke.edu/courses/spring00/cps100/assign/trees/diameter.html
Find Number of Nodes on the Longest Path in Binary Tree so one thing is sure that this path comprises on two leaves with maximum distance in BT..isn't it
Finding The Longest Path in Binary Tree will use the algorithms used by Diameter of Tree
PS:Don't confused with finding the maximum distance between two nodes in Binary Tree
its completely different algorithm & it has also been solved so u can search in blog.
Algorithm Used to Calculate Diameter/ finding two nodes which are separated by maximum difference.
The diameter of a tree (sometimes called the width) is the number of nodes on the longest path between two leaves in the tree. The diagram below shows two trees each with same 7 as a diameter but different orientation. (also note that there is more than one path in each tree of length nine, but no path longer than nine nodes).
Diameter 7
Diameter 7
The diameter of a tree T is the largest of the following quantities:
1 the diameter of T’s left subtree
2 the diameter of T’s right subtree
3 the longest path between leaves that goes through the root of T (this can be computed from the heights of the subtrees of T)
#include
#include
/* A binary tree node has data, pointer to left child
and a pointer to right child */
struct node
{
int data;
struct node* left;
struct node* right;
};
/* function to create a new node of tree and returns pointer */
struct node* newNode(int data);
/* returns max of two integers */
int max(int a, int b);
/* The function Compute the "height" of a tree. Height is the
number f nodes along the longest path from the root node
down to the farthest leaf node.*/
int height(struct node* node)
{
/* base case tree is empty */
if(node == NULL)
return 0;
/* If tree is not empty then height = 1 + max of left
height and right heights */
return 1 + max(height(node->left), height(node->right));
}
/* Function to get diameter of a binary tree */
int diameter(struct node * tree)
{
/* base case where tree is empty */
if (tree == 0)
return 0;
/* get the height of left and right sub-trees */
int lheight = height(tree->left);
int rheight = height(tree->right);
/* get the diameter of left and right sub-trees */
int ldiameter = diameter(tree->left);
int rdiameter = diameter(tree->right);
/* Return max of following three
1) Diameter of left subtree
2) Diameter of right subtree
3) Height of left subtree + height of right subtree + 1 */
return max(lheight + rheight + 1, max(ldiameter, rdiameter));
}
/* UTILITY FUNCTIONS TO TEST diameter() FUNCTION */
/* Helper function that allocates a new node with the
given data and NULL left and right pointers. */
struct node* newNode(int data)
{
struct node* node = (struct node*)
malloc(sizeof(struct node));
node->data = data;
node->left = NULL;
node->right = NULL;
return(node);
}
/* returns maximum of two integers */
int max(int a, int b)
{
return (a >= b)? a: b;
}
/* Driver program to test above functions*/
int main()
{
/* Constructed binary tree is
1 D=4 lh=2,rh=1
/ \
D=3,rh=1 2 3
lh=1 / \
4 5 D=1,lh=rh=0
*/
struct node *root = newNode(1);
root->left = newNode(2);
root->right = newNode(3);
root->left->left = newNode(4);
root->left->right = newNode(5);
printf("Diameter of the given binary tree is %d\n", diameter(root));
getchar();
return 0;
}
Time Complexity (N^2)
Space Complexity O(1)
Run Here https://ideone.com/s9OdR
Optimization(2nd Method)
The above implementation can be optimized by calculating the height in the same recursion rather than calling a height() separately. This optimization reduces time complexity to O(n).
#include
#include
/* A binary tree node has data, pointer to left child
and a pointer to right child */
struct node
{
int data;
struct node* left;
struct node* right;
};
/* function to create a new node of tree and returns pointer */
struct node* newNode(int data);
/* UTILITY FUNCTIONS TO TEST diameter() FUNCTION */
/*The second parameter is to store the height of tree.
Initially, we need to pass a pointer to a location with value
as 0. So, function should be used as follows:
int height = 0;
struct node *root = SomeFunctionToMakeTree();
int diameter = diameterOpt(root, &height); */
int diameterOpt(struct node *root, int* height)
{
/* lh --> Height of left subtree
rh --> Height of right subtree */
int lh = 0, rh = 0;
/* ldiameter --> diameter of left subtree
rdiameter --> Diameter of right subtree */
int ldiameter = 0, rdiameter = 0;
if(root == NULL)
{
*height = 0;
return 0; /* diameter is also 0 */
}
/* Get the heights of left and right subtrees in lh and rh
And store the returned values in ldiameter and ldiameter */
ldiameter = diameterOpt(root->left, &lh);
rdiameter = diameterOpt(root->right, &rh);
/* Height of current node is max of heights of left and
right subtrees plus 1*/
*height = max(lh, rh) + 1;
return max(lh + rh + 1, max(ldiameter, rdiameter));
}
/* Helper function that allocates a new node with the
given data and NULL left and right pointers. */
struct node* newNode(int data)
{
struct node* node = (struct node*)
malloc(sizeof(struct node));
node->data = data;
node->left = NULL;
node->right = NULL;
return(node);
}
/* returns maximum of two integers */
int max(int a, int b)
{
return (a >= b)? a: b;
}
/* Driver program to test above functions*/
int main()
{
/* Constructed binary tree is
1
/ \
2 3
/ \
4 5
*/
struct node *root = newNode(1);
root->left = newNode(2);
root->right = newNode(3);
root->left->left = newNode(4);
root->left->right = newNode(5);
int height=0;
printf("Diameter of the given binary tree is %d\n", diameter(root,&height));
getchar();
return 0;
}
Time Complexity O(n)
Space Complexity O(1)
Run Here https://ideone.com/uSPq0
More Info http://www.cs.duke.edu/courses/spring00/cps100/assign/trees/diameter.html
Saturday, April 30, 2011
How to find if a node/pointer corrupted in a linked list
How would you find out if one of the pointers in a linked list is corrupted or not?
This is a really good interview question. The reason is that linked lists are used in a wide variety of scenarios and being able to detect and correct pointer corruptions might be a very valuable tool. For example, data blocks associated with files in a file system are usually stored as linked lists. Each data block points to the next data block. A single corrupt pointer can cause the entire file to be lost!
1 Discover & Fix Bugs
Discover and fix bugs when they corrupt the linked list and not when effect becomes visible in some other part of the program. Perform frequent consistency checks (to see if the linked list is indeed holding the data that you inserted into it).
2 set Pointer to NUll after Freeing Object
It is good programming practice to set the pointer value to NULL immediately after freeing the memory pointed at by the pointer. This will help in debugging, because it will tell you that the object was freed somewhere beforehand. Keep track of how many objects are pointing to a object using reference counts if required.
3 Use Debugger Tool Like DDD,Purify,
Use a good debugger to see how the datastructures are getting corrupted and trace down the problem. Debuggers like ddd on linux and memory profilers like Purify, Electric fence are good starting points. These tools should help you track down heap corruption issues easily.
4.Avoid Global Variable
Avoid global variables when traversing and manipulating linked lists. Imagine what would happen if a function which is only supposed to traverse a linked list using a global head pointer accidently sets the head pointer to NULL!.
5 Check Add& Delete Node After such Opeartion
Its a good idea to check the addNode() and the deleteNode() routines and test them for all types of scenarios. This should include tests for inserting/deleting nodes at the front/middle/end of the linked list, working with an empty linked list, running out of memory when using malloc() when allocating memory for new nodes, writing through NULL pointers, writing more data into the node fields then they can hold (resulting in corrupting the (probably adjacent) “prev” and “next” pointer fields), make sure bug fixes and enhancements to the linked list code are reviewed and well tested (a lot of bugs come from quick and dirty bug fixing), log and handle all possible errors (this will help you a lot while debugging), add multiple levels of logging so that you can dig through the logs. The list is endless…
6.Keep Track of Number of Nodes After Every Node after Initializing Linked List
Each node can have an extra field associated with it. This field indicates the number of nodes after this node in the linked list. This extra field needs to be kept up-to-date when we inserte or delete nodes in the linked list (It might become slightly complicated when insertion or deletion happens not at end, but anywhere in the linked list). Then, if for any node, p->field > 0 and p->next == NULL, it surely points to a pointer corruption.
You could also keep the count of the total number of nodes in a linked list and use it to check if the list is indeed having those many nodes or not.
The problem in detecting such pointer corruptions in C is that its only the programmer who knows that the pointer is corrupted. The program has no way of knowing that something is wrong. So the best way to fix these errors is check your logic and test your code to the maximum possible extent. I am not aware of ways in C to recover the lost nodes of a corrupted linked list. C does not track pointers so there is no good way to know if an arbitrary pointer has been corrupted or not. The platform may have a library service that checks if a pointer points to valid memory (for instance on Win32 there is a IsBadReadPtr, IsBadWritePtr API.) If you detect a cycle in the link list, it’s definitely bad. If it’s a doubly linked list you can verify, pNode->Next->Prev == pNode.
I have a hunch that interviewers who ask this question are probably hinting at something called Smart Pointers in C++. Smart pointers are particularly useful in the face of exceptions as they ensure proper destruction of dynamically allocated objects. They can also be used to keep track of dynamically allocated objects shared by multiple owners. This topic is out of scope here, but you can find lots of material on the Internet for Smart Pointers.
This is a really good interview question. The reason is that linked lists are used in a wide variety of scenarios and being able to detect and correct pointer corruptions might be a very valuable tool. For example, data blocks associated with files in a file system are usually stored as linked lists. Each data block points to the next data block. A single corrupt pointer can cause the entire file to be lost!
1 Discover & Fix Bugs
Discover and fix bugs when they corrupt the linked list and not when effect becomes visible in some other part of the program. Perform frequent consistency checks (to see if the linked list is indeed holding the data that you inserted into it).
2 set Pointer to NUll after Freeing Object
It is good programming practice to set the pointer value to NULL immediately after freeing the memory pointed at by the pointer. This will help in debugging, because it will tell you that the object was freed somewhere beforehand. Keep track of how many objects are pointing to a object using reference counts if required.
3 Use Debugger Tool Like DDD,Purify,
Use a good debugger to see how the datastructures are getting corrupted and trace down the problem. Debuggers like ddd on linux and memory profilers like Purify, Electric fence are good starting points. These tools should help you track down heap corruption issues easily.
4.Avoid Global Variable
Avoid global variables when traversing and manipulating linked lists. Imagine what would happen if a function which is only supposed to traverse a linked list using a global head pointer accidently sets the head pointer to NULL!.
5 Check Add& Delete Node After such Opeartion
Its a good idea to check the addNode() and the deleteNode() routines and test them for all types of scenarios. This should include tests for inserting/deleting nodes at the front/middle/end of the linked list, working with an empty linked list, running out of memory when using malloc() when allocating memory for new nodes, writing through NULL pointers, writing more data into the node fields then they can hold (resulting in corrupting the (probably adjacent) “prev” and “next” pointer fields), make sure bug fixes and enhancements to the linked list code are reviewed and well tested (a lot of bugs come from quick and dirty bug fixing), log and handle all possible errors (this will help you a lot while debugging), add multiple levels of logging so that you can dig through the logs. The list is endless…
6.Keep Track of Number of Nodes After Every Node after Initializing Linked List
Each node can have an extra field associated with it. This field indicates the number of nodes after this node in the linked list. This extra field needs to be kept up-to-date when we inserte or delete nodes in the linked list (It might become slightly complicated when insertion or deletion happens not at end, but anywhere in the linked list). Then, if for any node, p->field > 0 and p->next == NULL, it surely points to a pointer corruption.
You could also keep the count of the total number of nodes in a linked list and use it to check if the list is indeed having those many nodes or not.
The problem in detecting such pointer corruptions in C is that its only the programmer who knows that the pointer is corrupted. The program has no way of knowing that something is wrong. So the best way to fix these errors is check your logic and test your code to the maximum possible extent. I am not aware of ways in C to recover the lost nodes of a corrupted linked list. C does not track pointers so there is no good way to know if an arbitrary pointer has been corrupted or not. The platform may have a library service that checks if a pointer points to valid memory (for instance on Win32 there is a IsBadReadPtr, IsBadWritePtr API.) If you detect a cycle in the link list, it’s definitely bad. If it’s a doubly linked list you can verify, pNode->Next->Prev == pNode.
I have a hunch that interviewers who ask this question are probably hinting at something called Smart Pointers in C++. Smart pointers are particularly useful in the face of exceptions as they ensure proper destruction of dynamically allocated objects. They can also be used to keep track of dynamically allocated objects shared by multiple owners. This topic is out of scope here, but you can find lots of material on the Internet for Smart Pointers.
Subscribe to:
Posts
(
Atom
)



